![]()
Updated Oct-2024 Exam Engine for QSDA2024 Exam Free Demo & 365 Day Updates
Exam Passing Guarantee QSDA2024 Exam with Accurate Quastions!
NEW QUESTION # 25
A data architect inherits an app that takes too long to load and overruns the data load window.
The app pulls all records (new and historical) from three large databases. The reload process puts a heavy load on the source database servers. All of the data is required for analysis.
What should the data architect do?
- A. Implement ODAG to split out the app into smaller chunks
- B. Implement Direct Discovery with partial load
- C. Implement incremental load on each database using QVD files
- D. Make sure the individual reload tasks in the QMC are not running in parallel
Answer: C
Explanation:
The scenario describes an app that is experiencing long load times due to the need to pull all records, both new and historical, from three large databases. This situation puts a strain on both the Qlik environment and the source databases. Given that all data is required for analysis, a full reload each time can be inefficient and resource-intensive.
Implementingincremental loadis a widely recommended approach in such cases. Incremental loading allows you to load only new or changed data since the last reload, rather than reloading all the data every time. This significantly reduces the time and resources required for reloading, as only a subset of the data needs to be processed during each reload. QVD (QlikView Data) files are typically used to store the historical data, while only the new or updated records are fetched from the source databases.
This approach would help:
* Reduce the load on the source databases.
* Shorten the data reload window.
* Maintain historical data efficiently while ensuring that all new data is captured.
NEW QUESTION # 26
A data architect executes the following script:
Which values does the OrderDate field contain after executing the script?
- A. 20210131, 2020/01/31, 31/01/2019, 9999
- B. 20210131, 2020/01/31, 31/01/2019, 0
- C. 20210131, 2020/01/31, 31/01/2019
- D. 20210131, 2020/01/31, 31/01/2019, 31/12/2022
Answer: D
Explanation:
In the script provided, the alt() function is used to handle various date formats. The alt() function in Qlik Sense evaluates a list of expressions and returns the first valid expression. If none of the expressions are valid, it returns the last argument provided (in this case, '31/12/2022').
Step-by-step breakdown:
* The alt() function checks the Date field for three different formats:
* YYYYMMDD
* YYYY/MM/DD
* DD/MM/YYYY
* If none of these formats match the value in the Date field, the default date '31/12/2022' is assigned.
Values in the Date field:
* 20210131: Matches the first format YYYYMMDD.
* 2020/01/31: Matches the second format YYYY/MM/DD.
* 31/01/2019: Matches the third format DD/MM/YYYY.
* 9999: Does not match any of the formats, so the alt() function returns the default value '31/12/2022'.
NEW QUESTION # 27
Exhibit.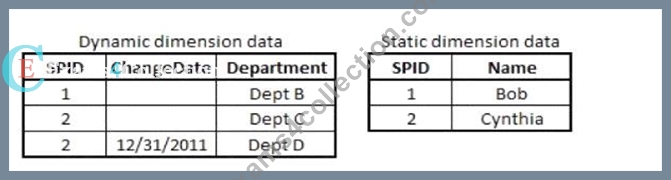
A large electronics company re-assigns sales people once per year from one Department to another.
SPID is the Salesperson ID; the SPID for each individual sales person Name remains constant. The Department for a SPID may change; each change is stored in the Dynamic Dimension data.
Four tables need to be linked correctly: a transaction table, a dynamic salesperson dimension, a static salesperson dimension, and a department dimension.
Which script prefix should the data architect use?
- A. IntervalMatch
- B. Merge
- C. Partial Reload
- D. Semantic
Answer: A
Explanation:
In the scenario described, the Dynamic Dimension data tracks changes in department assignments for salespeople over time. To correctly link the transaction data with the salesperson data and ensure that sales are associated with the correct department based on the date, an IntervalMatch function should be used.
IntervalMatchis designed to match discrete data (like transaction dates) with a range of dates. In this case, each salesperson's department assignment is valid over a period of time, and the IntervalMatch function can be used to link the transaction data with the correct department for each salesperson based on the transaction date.
* Option A (Merge):This option is incorrect as it refers to combining data sets, which doesn't address the need to handle the dynamic, date-based department assignments.
* Option B (IntervalMatch):This is the correct choice because it allows you to match each transaction with the correct department assignment based on the ChangeDate in the Dynamic Dimension data.
* Option C (Partial Reload):This refers to reloading only part of the data, which is not relevant to linking tables based on date ranges.
* Option D (Semantic):This option is not applicable as it refers to a broader approach to data modeling and interpretation rather than specifically linking data based on time intervals.
Thus,IntervalMatchis the correct method for linking the transaction data with the dynamic salesperson dimension, ensuring that each transaction is associated with the correct department based on the historical assignment data.
NEW QUESTION # 28
Exhibit.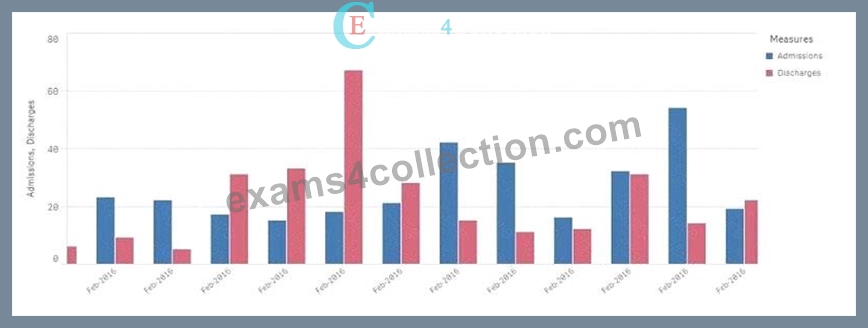
A chart for monthly hospital admissions and discharges incorrectly displays the month and year values on the x-axis.
The date format for the source data field "Common Date" is M/D/YYYY. This format was used in a calculated field named "Month-Year" in the data manager when the data model was first built.
Which expression should the data architect use to fix this issue?
- A. Date(MonthsStart([Common Date]),'VMM-YYYY')
- B. Date([Comraon Date],'MMM-YYYY')
- C. Date(MonthStart([Common Date]),'MMM-YYYY')
- D. Date(InMontht[Common Date]),'MMM-YYYY')
Answer: C
Explanation:
The issue described relates to the incorrect display of month and year values on the x-axis of a chart. The source data has dates in the M/D/YYYY format, and a calculated field named Month-Year was created using this date format.
To correct the issue:
* The correct approach is to use the MonthStart() function, which returns the first date of the month for the provided date. This ensures consistency in month-year representation.
* The Date() function is then used to format the result of MonthStart() to the desired format of MMM- YYYY (e.g., Feb-2018).
Explanation of the Correct Expression:
* MonthStart([Common Date]): This ensures that all dates within a month are treated as the first day of that month, which is critical for accurate monthly aggregation.
* Date(..., 'MMM-YYYY'): This formats the result to show just the month and year in the correct format.
Using this expression ensures that the x-axis correctly displays the month-year values.
NEW QUESTION # 29
Refer to the exhibit.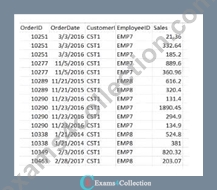
A data architect needs to build a dashboard that displays the aggregated sates for each sales representative. All aggregations on the data must be performed in the script.
Which script should the data architect use to meet these requirements?
- A.

- B.
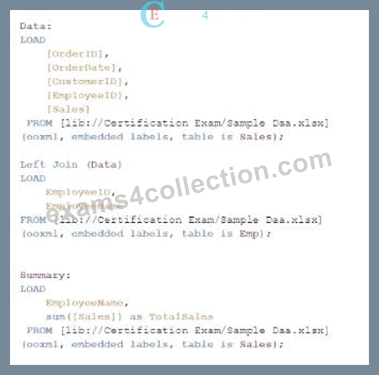
- C.

- D.
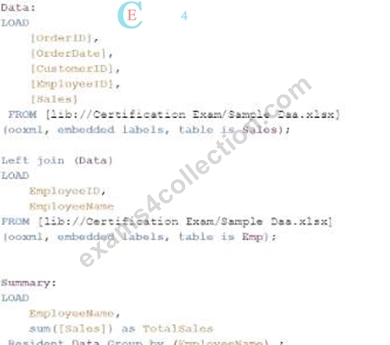
Answer: A
Explanation:
The goal is to display the aggregated sales for each sales representative, with all aggregations being performed in the script. Option C is the correct choice because it performs the aggregation correctly using a Group by clause, ensuring that the sum of sales for each employee is calculated within the script.
* Data Load:
* The Data table is loaded first from the Sales table. This includes the OrderID, OrderDate, CustomerID, EmployeeID, and Sales.
* Next, the Emp table is loaded containing EmployeeID and EmployeeName.
* Joining Data:
* A Left Join is performed between the Data table and the Emp table on EmployeeID, enriching the data with EmployeeName.
* Aggregation:
* The Summary table is created by loading the EmployeeName and calculating the total sales using the sum([Sales]) function.
* The Resident keyword indicates that the data is pulled from the existing tables in memory, specifically the Data table.
* The Group by clause ensures that the aggregation is performed correctly for each EmployeeName, summarizing the total sales for each employee.
Key Qlik Sense Data Architect References:
* Resident Load: This is a method to reuse data that is already loaded into the app's memory. By using a Resident load, you can create new tables or perform calculations like aggregation on the existing data.
* Group by Clause: The Group by clause is essential when performing aggregations in the script. It groups the data by specified fields and performs the desired aggregation function (e.g., sum, count).
* Left Join: Used to combine data from two tables. In this case, Left Join is used to enrich the sales data with employee names, ensuring that the sales data is associated correctly with the respective employee.
Conclusion:Option C is the most appropriate script for this task because it correctly performs the necessary joins and aggregations in the script. This ensures that the dashboard will display the correct aggregated sales per employee, meeting the data architect's requirements.
NEW QUESTION # 30
The data architect has been tasked with building a sales reporting application.
* Part way through the year, the company realigned the sales territories
* Sales reps need to track both their overall performance, and their performance in their current territory
* Regional managers need to track performance for their region based on the date of the sale transaction
* There is a data table from HR that contains the Sales Rep ID, the manager, the region, and the start and end dates for that assignment
* Sales transactions have the salesperson in them, but not the manager or region.
What is the first step the data architect should take to build this data model to accurately reflect performance?
- A. Build a star schema around the sales table, and use the Hierarchy function to join the HR data to the model
- B. Use the IntervalMatch function with the transaction date and the HR table to generate point in time data
- C. Implement an "as of calendar against the sales table and use ApplyMap to fill in the needed management data
- D. Create a link table with a compound key of Sales Rep / Transaction Date to find the correct manager and region
Answer: B
Explanation:
In the provided scenario, the sales territories were realigned during the year, and it is necessary to track performance based on the date of the sale and the salesperson's assignment during that period. The IntervalMatch function is the best approach to create a time-based relationship between the sales transactions and the sales territory assignments.
* IntervalMatch: This function is used to match discrete values (e.g., transaction dates) with intervals (e.
g., start and end dates for sales territory assignments). By matching the transaction dates with the intervals in the HR table, you can accurately determine which territory and manager were in effect at the time of each sale.
Using IntervalMatch, you can generate point-in-time data that accurately reflects the dynamic nature of sales territory assignments, allowing both sales reps and regional managers to track performance over time.
NEW QUESTION # 31
A company's analytics team is migrating from QlikView to Qlik Sense. During the transition there is an opportunity to improve overall reporting.
Which set of criteria must the data architect consider while planning for the migration?
- A. Application size, application theme, storytelling, data model, IT use case
- B. Application metadata, application theme, user sessions, load script, IT use case
- C. User sessions, source data architecture, compatibility, data model, business use case
- D. QlikView archival, source data architecture, load script, data model, business use case
Answer: D
Explanation:
During the transition from QlikView to Qlik Sense, the analytics team has the opportunity to improve the overall reporting. To ensure a smooth migration while optimizing the new environment, the data architect needs to consider several key factors.
Option Cis the best choice because it encompasses the essential aspects of a migration project:
* QlikView Archival:
* Archiving QlikView applications is crucial to ensure that historical data and applications are preserved and can be referenced if needed in the future. This step is important to maintain continuity and provide a fallback option if required during the transition.
* Source Data Architecture:
* Understanding the existing source data architecture is critical to ensure that the new Qlik Sense applications can seamlessly connect to the data sources. This also helps in identifying opportunities to optimize or re-architect the data pipelines for better performance in Qlik Sense.
* Load Script:
* The load script from QlikView might need to be revised or optimized for Qlik Sense. It's important to ensure that the script is compatible and takes advantage of Qlik Sense's capabilities, such as improved data handling, better inline transformations, and enhanced scripting functions.
* Data Model:
* Reviewing and possibly redesigning the data model is essential during the migration. Qlik Sense's associative engine allows for more flexibility, and this is an opportunity to improve the data model for better performance, scalability, and user experience.
* Business Use Case:
* Understanding the business use case is vital to ensure that the new Qlik Sense applications meet the business requirements effectively. This includes making sure that the new reports and dashboards are aligned with the business goals and provide the necessary insights.
References:
* Qlik Migration Guide: When migrating from QlikView to Qlik Sense, it's important to consider not just the technical aspects but also the business implications and opportunities for improvement.
* Qlik Documentation on Data Modeling and Load Script Optimization: These resources provide best practices on how to optimize load scripts and data models during migration to ensure smooth operation and better performance in Qlik Sense.
NEW QUESTION # 32
A data architect needs to acquire social media data for the past 10 years. The data architect needs to track all changes made to the source data, include all relevant fields, and reload the application four times a day.
What information does the data architect need?
- A. A field with ModificationTime, a primary key field to sort out updated records, insert and update records, remove records
- B. A field with ModificationTime, a primary key field to sort out updated records, insert and append records, update records
- C. A field with record creation time, a secondary key field to remove deleted records, configure reload task to load four times a day
- D. A field with social media source, a set of key fields to sort out updated records, configure reload task to load four times a day
Answer: A
Explanation:
The scenario describes a need to track social media data over the past 10 years, capturing all changes (inserts, updates, deletes) while reloading the data four times a day.
To manage this:
* ModificationTime: This field is essential for tracking changes over time. It indicates when a record was last modified, allowing the script to determine whether it needs to insert, update, or delete records.
* Primary Key Field: A primary key is crucial for uniquely identifying records. It enables the script to match records in the source with those already loaded, facilitating updates and deletions.
* Insert and Update Records: The script should handle both inserting new records and updating existing ones based on the ModificationTime.
* Remove Records: If records are deleted in the source, they should also be removed in the Qlik Sense data model to maintain consistency.
This approach ensures that all changes in the social media data are accurately captured and reflected in the Qlik Sense application.
NEW QUESTION # 33
Exhibit.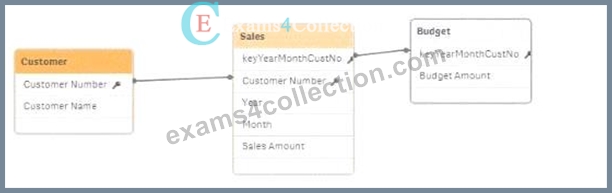
Refer to the exhibit.
The data architect needs to build a model that contains Sales and Budget data for each customer. Some customers have Sales without a Budget, and other customers have a Budget with no Sales.
During loading, the data architect resolves a synthetic key by creating the composite key.
For validation, the data architect creates a table that contains Customer, Month, Sales, and Budget columns.
What will the data architect see when selecting a month?
- A. Customer Names and Budaets records for the selected month. Sales column can contain null or non-null values
- B. Customer Names and Sales records for the selected month but with only non-null values in Budget column
- C. All Customer Names for both Sales and Budget records for the selected month
- D. Customer Names and Sales records for the selected month, Budgets column can contain null or non-null values
Answer: D
Explanation:
In the scenario where the data model is built with a composite key (keyYearMonthCustNo) to resolve synthetic keys, the following outcomes occur:
* Sales and Budget Data Integration:
* The composite key ensures that each combination of Year, Month, and Customer is uniquely represented in the combined Sales and Budget data.
* During data selection (e.g., when a specific month is selected), Qlik Sense will show all the customer names that have either Sales or Budget data associated with that month.
* Resulting Data View:
* For the selected month, customers with sales records will display their Sales data. However, if the corresponding Budget data is missing, the Budget column will contain null values.
* Similarly, if a customer has a Budget but no Sales data for the selected month, the Sales column will show null values.
Validation Outcome:When the data architect selects a month, they will see the following:
* Customer Names and Sales recordsfor the selected month, where the Sales column will have values and the Budget column may contain null or non-null values depending on the data availability.
NEW QUESTION # 34
A startup company is about have its Initial Public Offering (IPO) on the New York Stock Exchange.
This startup company has used Qlik Sense for many years for data-based decision making for Sales and Marketing efforts, as well as for input into Financial Reporting. The startup's Qlik Sense applications use variables that have different values at different points in time.
Due to the increased rigor required in record keeping for public companies, these variables must be clearly recorded in the script reload logs of the Qlik Sense applications. These logs are refreshed daily.
The data architect wants to have the variables names, with their current values,writteninto the script reload logs. Which script statement should the data architect use?
- A. Tag
- B. LogDetail
- C. REM
- D. Trace
Answer: D
Explanation:
In the scenario where the startup company is preparing for an IPO, there is an increased need for meticulous record-keeping, including the recording of variable values used in Qlik Sense applications. The TRACE statement is the most suitable option for logging variable values during script execution.
* TRACE: This statement writes custom messages, including variable values, to the script execution log.
By using TRACE, you can ensure that every reload log contains the names and current values of all relevant variables, providing the necessary transparency and traceability.
For example, the script could include:
TRACE $(VariableName);
This command will output the variable's value in the script log, ensuring it is recorded for audit purposes.
NEW QUESTION # 35
A data architect executes the following script: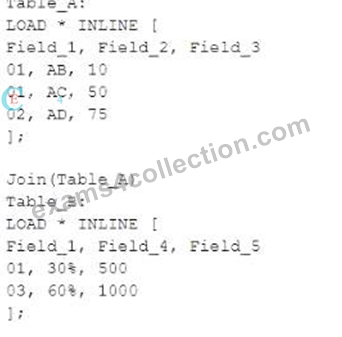
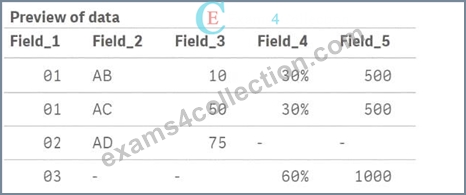
What will be the result of Table.A?
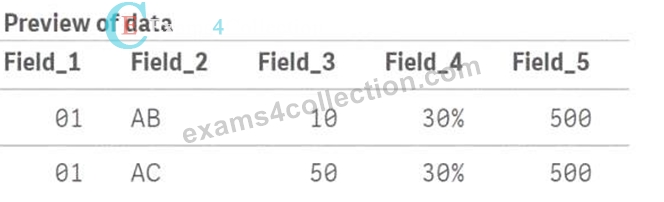
- A.
- B.

- C.
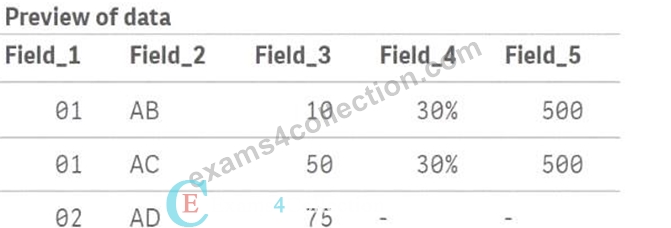
- D.
Answer: C
Explanation:
In the script provided, there are two tables being loaded inline: Table_A and Table_B. The script uses the Join function to combine Table_B with Table_A based on the common field Field_1. Here's how the join operation works:
* Table_Ainitially contains three records with Field_1 values of 01, 01, and 02.
* Table_Bcontains two records with Field_1 values of 01 and 03.
When Join(Table_A) is executed, Qlik Sense will perform an inner join by default, meaning it will join rows from Table_B to Table_A where Field_1 matches in both tables. The result is:
* For Field_1 = 01, there are two matches in Table_A and one match in Table_B. This results in two records in the joined table where Field_4 and Field_5 values from Table_B are repeated for each match in Table_A.
* For Field_1 = 02, there is no corresponding Field_1 = 02 in Table_B, so the Field_4 and Field_5 values for this record will be null.
* For Field_1 = 03, there is no corresponding Field_1 = 03 in Table_A, so the record from Table_B with Field_1 = 03 is not included in the final joined table.
Thus, the correct output will look like this:
* Field_1 = 01, Field_2 = AB, Field_3 = 10, Field_4 = 30%, Field_5 = 500
* Field_1 = 01, Field_2 = AC, Field_3 = 50, Field_4 = 30%, Field_5 = 500
* Field_1 = 02, Field_2 = AD, Field_3 = 75, Field_4 = null, Field_5 = null
NEW QUESTION # 36
A data architect needs to load large amounts of data from a database that is continuously updated.
* New records are added, and existing records get updated and deleted.
* Each record has a LastModified field.
* All existing records are exported into a QVD file.
* The data architect wants to load the records into Qlik Sense efficiently.
Which steps should the data architect take to meet these requirements?
- A. 1. Load the existing data from the QVD.
2. Load new and updated data from the database. Concatenate with the table loaded from the QVD.
3. Create a separate table for the deleted rows and use a WHERE NOT EXISTS to remove these records. - B. 1. Load the new and updated data from the database.
2. Load the existing data from the QVD without the updated rows that have just been loaded from the database and concatenate with the new and updated records.
3. Load all records from the key field from the database and use an INNER JOIN on the previous table. - C. 1. Use a partial LOAD to load new and updated data from the database.
2. Load the existing data from the QVD without the updated rows that have just been loaded from the database and concatenate with the new and updated records.
3. Use the PEEK function to remove the deleted rows. - D. 1. Load the existing data from the QVD.
2. Load the new and updated data from the database without the rows that have just been loaded from the QVD and concatenate with data from the QVD.
3. Load all records from the key field from the database and use an INNER JOIN on the previous table.
Answer: A
Explanation:
When dealing with a database that is continuously updated with new records, updates, and deletions, an efficient data load strategy is necessary to minimize the load time and keep the Qlik Sense data model up-to- date.
Explanation of Steps:
* Load the existing data from the QVD:
* This step retrieves the already loaded and processed data from a previous session. It acts as a base to which new or updated records will be added.
* Load new and updated data from the database. Concatenate with the table loaded from the QVD:
* The next step is to load only the new and updated records from the database. This minimizes the amount of data being loaded and focuses on just the changes.
* The new and updated records are then concatenated with the existing data from the QVD, creating a combined dataset that includes all relevant information.
* Create a separate table for the deleted rows and use a WHERE NOT EXISTS to remove these records:
* A separate table is created to handle deletions. The WHERE NOT EXISTS clause is used to identify and remove records from the combined dataset that have been deleted in the source database.
NEW QUESTION # 37
Refer to the exhibit.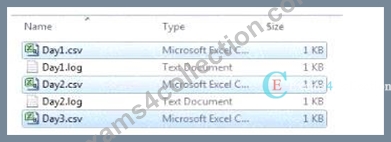
A system creates log files and csv files daily and places these files in a folder. The log files are named automatically by the source system and change regularly. All csv files must be loaded into Qlik Sense for analysis.
Which method should be used to meet the requirements?
- A.

- B.

- C.

- D.

Answer: A
Explanation:
In the scenario described, the goal is to load all CSV files from a directory into Qlik Sense, while ignoring the log files that are also present in the same directory. The correct approach should allow for dynamic file loading without needing to manually specify each file name, especially since the log files change regularly.
Here's whyOption Bis the correct choice:
* Option A:This method involves manually specifying a list of files (Day1, Day2, Day3) and then iterating through them to load each one. While this method would work, it requires knowing the exact file names in advance, which is not practical given that new files are added regularly. Also, it doesn't handle dynamic file name changes or new files added to the folder automatically.
* Option B:This approach uses a wildcard (*) in the file path, which tells Qlik Sense to load all files matching the pattern (in this case, all CSV files in the directory). Since the csv file extension is explicitly specified, only the CSV files will be loaded, and the log files will be ignored. This method is efficient and handles the dynamic nature of the file names without needing manual updates to the script.
* Option C:This option is similar to Option B but targets text files (txt) instead of CSV files. Since the requirement is to load CSV files, this option would not meet the needs.
* Option D:This option uses a more complex approach with filelist() and a loop, which could work, but it's more complex than necessary. Option B achieves the same result more simply and directly.
Therefore,Option Bis the most efficient and straightforward solution, dynamically loading all CSV files from the specified directory while ignoring the log files, as required.
NEW QUESTION # 38
A data architect receives an error while running script.
What will happen to the existing data model?
- A. The latest error-free data model will be maintained.
- B. Newly loaded tables will be merged with the existing data model until the error is resolved.
- C. The data model will be replaced with the tables that were successfully loaded before the error.
- D. The data model will be removed from the application.
Answer: A
Explanation:
In Qlik Sense, when a data load script is executed and an error occurs, the script execution is halted immediately, and any tables that were being loaded at the time of the error are discarded. However, the existing data model-i.e., the last successfully loaded data model-remains intact and is not affected by the failed script. This ensures that the application retains the last known good state of the data, avoiding any partial or inconsistent data loads that could occur due to an error.
When the script encounters an error:
* The tables that were successfully loaded prior to the error are retained in the session, but these tables are not merged with the existing data model.
* The existing data model before the script was executed remains unchanged and is maintained.
* No partial or incomplete data is loaded into the application; hence, the data model remains consistent and reliable.
Qlik Sense Data Architect ReferencesThis behavior is designed to protect the integrity of the data model. In scenarios where script execution fails, the user can debug and fix the script without risking the data integrity of the existing application. The key references include:
* Qlik Help Documentation: Provides detailed information on how Qlik Sense handles script errors, highlighting that the existing data model remains unchanged after an error.
* Data Load Editor Practices: Best practices dictate ensuring that the script is fully functional before executing it to avoid data inconsistency. In cases where an error occurs, understanding that the current data model is maintained helps in strategic debugging and script correction.
NEW QUESTION # 39
Exhibit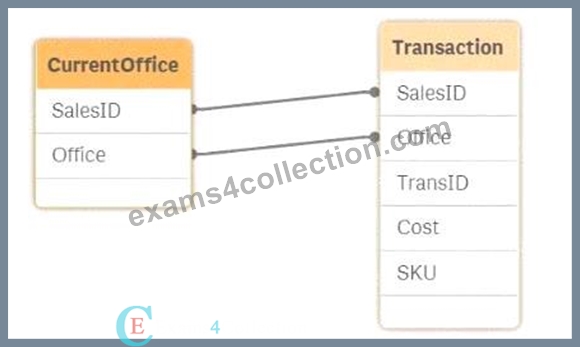
Refer to the exhibit.
The salesperson ID and the office to which the salesperson belongs is stored for each transaction. The data model also contains the current office for the salesperson. The current office of the salesperson and the office the salesperson was in when the transaction occurred must be visible. The current source table view of the model is shown. A data architect must resolve the synthetic key.
How should the data architect proceed?
- A. Alias Office to CurrentOffice In the CurrentOffice table
- B. Force concatenation between the tables
- C. Inner Join the Transaction table to the CurrentOffice table
- D. Comment out the Office in the Transaction table
Answer: A
Explanation:
In the provided data model, both the CurrentOffice and Transaction tables contain the fields SalesID and Office. This leads to the creation of a synthetic key in Qlik Sense because of the two common fields between the two tables. A synthetic key is created automatically by Qlik Sense when two or more tables have two or more fields in common. While synthetic keys can be useful in some scenarios, they often lead to unwanted and unexpected results, so it's generally advisable to resolve them.
In this case, the goal is to have both the current office of the salesperson and the office where the transaction occurred visible in the data model. Here's how each option compares:
* Option A: Comment out the Office in the Transaction table:This would remove the Office field from the Transaction table, which would prevent you from seeing which office the salesperson was in when the transaction occurred. This option does not meet the requirement.
* Option B: Inner Join the Transaction table to the CurrentOffice table:Performing an inner join would merge the two tables based on the common SalesID and Office fields. However, this might result in a loss of data if there are sales records in the Transaction table that don't have a corresponding record in the CurrentOffice table or vice versa. This approach might also lead to unexpected results in your analysis.
* Option C: Alias Office to CurrentOffice In the CurrentOffice table:By renaming the Office field in the CurrentOffice table to CurrentOffice, you prevent the synthetic key from being created. This allows you to differentiate between the salesperson's current office and the office where the transaction occurred. This approach maintains the integrity of your data and allows for clear analysis.
* Option D: Force concatenation between the tables:Forcing concatenation would combine the rows of both tables into a single table. This would not solve the issue of distinguishing between the current office and the office at the time of the transaction, and it could lead to incorrect data associations.
Given these considerations, the best approach to resolve the synthetic key while fulfilling the requirement of having both the current office and the office at the time of the transaction visible is toAlias Office to CurrentOffice in the CurrentOffice table. This ensures that the data model will accurately represent both pieces of information without causing synthetic key issues.
NEW QUESTION # 40
Exhibit.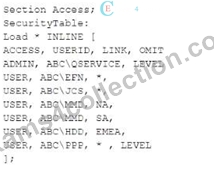
The Section Access security table for an app is shown. User ABC\PPP opens a Qlik Sense app with a table using the field called LEVEL on one of the table columns.
Which is the result?
- A. The user gets a 'Field not found' error.
- B. The user gets an 'Incomplete visualization' error.
- C. The table is displayed without the LEVEL column.
- D. The table is removed from the user interface.
Answer: C
Explanation:
In this scenario, the Section Access security table controls user access to data within the Qlik Sense app. The user in question, ABC\PPP, has a specific entry in the security table that determines their access rights to the LEVEL field.
Understanding Section Access:
* Section Accessis used to enforce security by restricting access to certain data based on the user's credentials.
* In the security table provided, the USER role for ABC\PPP is set to have access to all data (* in the LINK field), but the OMIT field is set to LEVEL. The OMIT field in Section Access specifies fields that should be omitted from the user's view.
Outcome:
* Since the OMIT field for user ABC\PPP is set to LEVEL, this user will not have access to the LEVEL field in the Qlik Sense application.
Option D: The table is displayed without the LEVEL columnis the correct outcome.
* Explanation: When user ABC\PPP opens the app, the LEVEL field is omitted from their view. Any table or visualization that uses the LEVEL field will have that field excluded from display. The rest of the data and columns in the table will be visible, but the LEVEL column will not be shown.
References:
* Qlik Sense Security and Section Access Documentation: The OMIT functionality in Section Access is specifically designed to remove fields from the user's access, ensuring that sensitive or unnecessary data is not exposed.
NEW QUESTION # 41
A company generates l GB of ticketing data daily. The data is stored in multiple tables. Business users need to see trends of tickets processed for the past 2 years. Users very rarely access the transaction-level data for a specific date. Only the past 2 years of data must be loaded, which is 720 GB of data.
Which method should a data architect use to meet these requirements?
- A. Load only 2 years of data in an aggregated app and create a separate transaction app for occasional use
- B. Load only aggregated data for 2 years and apply filters on a sheet for transaction data
- C. Load only 2 years of data and use best practices in scripting and visualization to calculate and display aggregated data
- D. Load only aggregated data for 2 years and use On-Demand App Generation (ODAG) for transaction data
Answer: D
Explanation:
In this scenario, the company generates 1 GB of ticketing data daily, accumulating up to 720 GB over two years. Business users mainly require trend analysis for the past two years and rarely need to access the transaction-level data. The objective is to load only the necessary data while ensuring the system remains performant.
Option Cis the optimal choice for the following reasons:
* Efficiency in Data Handling:
* By loading only aggregated data for the two years, the app remains lean, ensuring faster load times and better performance when users interact with the dashboard. Aggregated data is sufficient for analyzing trends, which is the primary use case mentioned.
* On-Demand App Generation (ODAG):
* ODAG is a feature in Qlik Sense designed for scenarios like this one. It allows users to generate a smaller, transaction-level dataset on demand. Since users rarely need to drill down into transaction-level data, ODAG is a perfect fit. It lets users load detailed data for specific dates only when needed, thus saving resources and keeping the main application lightweight.
* Performance Optimization:
* Loading only aggregated data ensures that the application is optimized for performance. Users can analyze trends without the overhead of transaction-level details, and when they need more detailed data, ODAG allows for targeted loading of that data.
References:
* Qlik Sense Best Practices: Using ODAG is recommended when dealing with large datasets where full transaction data isn't frequently needed but should still be accessible.
* Qlik Documentation on ODAG: ODAG helps in maintaining a balance between performance and data availability by providing a method to load only the necessary details on demand.
NEW QUESTION # 42
A Chief Information Officer has hired Qlik to enhance the organization's inventory analytics. In the initial meeting, the client's focus was determined to be forecasting inventory levels.
Which stakeholder should be consulted first when gathering requirements?
- A. Product Buyer
- B. Vice President of Marketing
- C. SQL Developer
- D. Chief Information Officer
Answer: A
Explanation:
In this scenario, the focus of the project is to enhance inventory analytics, specifically targeting forecasting inventory levels. The primary goal is to understand the factors influencing inventory management and to build a model that helps in predicting future inventory needs.
Option A: Product Buyeris the correct stakeholder to consult first.
Here's why:
* Direct Involvement in Inventory Management:
* The Product Buyer is typically responsible for making decisions related to purchasing and maintaining inventory levels. They have a deep understanding of the factors that influence inventory needs, such as lead times, supplier reliability, demand forecasting, and purchasing cycles.
* Knowledge of Inventory Requirements:
* Since the project's primary focus is forecasting inventory levels, the Product Buyer will provide crucial insights into the variables that affect inventory and the data needed for accurate forecasting. They can guide what historical data is essential and what external factors might need to be considered in the forecasting model.
* Alignment with Business Objectives:
* By consulting the Product Buyer, the project can ensure that the inventory forecasting models align with the company's inventory management objectives, avoiding overstocking or understocking, and thus optimizing costs.
References:
* Qlik Project Management Best Practices: In analytics projects, particularly those focused on specific operational areas like inventory management, consulting the stakeholders who are closest to the operational data and decision-making processes ensures that the solution will be relevant and effective.
NEW QUESTION # 43
Exhibit.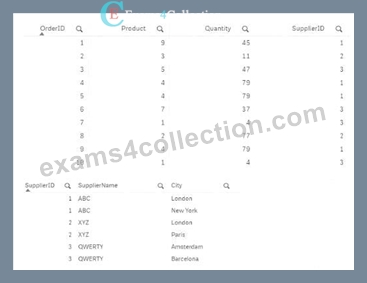
Refer to the exhibits.
The Orders table contains a list of orders and associated details. A data architect needs to replace the SupplierlD with the SupplierName using the second table as the source.
The output must be a single table.
Which script should the data architect use?
- A.

- B.

- C.

- D.

Answer: B
Explanation:
In this scenario, the data architect needs to replace the SupplierID in the Orders table with the corresponding SupplierName from the Suppliers table, and the desired output should be a single table that includes all the order details along with the SupplierName instead of the SupplierID.
Analyzing the Options:
* Option A:
* Uses a MAPPING LOAD followed by an APPLYMAP to replace SupplierID with SupplierName in the Orders table. However, the table is dropped afterward, which means it won't produce the required output.
* The MAPPING LOAD approach is generally used to map values but is not necessary in this context as we are combining data from two tables directly.
* Option B:
* This option attempts to LEFT JOIN the Products table with the Suppliers table, but it does not directly address replacing SupplierID with SupplierName in the Orders table.
* Additionally, it does not remove the SupplierID after the join, which is essential for the correct output.
* Option C:
* This option uses a LEFT JOIN with the DISTINCT keyword on the SupplierID field to avoid duplicates. The SupplierName is correctly joined to the Orders table, replacing the SupplierID.
* This approach is the most appropriate because it results in a single table containing all order details with the SupplierName instead of the SupplierID.
* Option D:
* Similar to Option A, but it also introduces an unnecessary renaming step with MAPPING LOAD.
It's redundant and does not improve the solution over Option C.
Correct Script Choice:
Option Cis the correct script because:
* It ensures that SupplierName replaces SupplierID in the Orders table using a LEFT JOIN.
* The DISTINCT keyword is applied to the SupplierID field to prevent duplicate rows during the join.
* The result is a single table containing the required information with SupplierName in place of SupplierID.
References:
* Qlik Sense Join Operations: Using the correct JOIN type and ensuring proper deduplication (with DISTINCT if necessary) is key to merging tables in Qlik Sense.
NEW QUESTION # 44
Users of a published app report incomplete visualizations. The data architect checks the app multiple times and cannot replicate the error. The error affects only one team.
Which is the most likely cause?
- A. A security rule has been applied to the sheet object.
- B. Section access restricts too many records.
- C. An Omit field has been applied.
- D. The affected users were NOT added to the Section Access table.
Answer: B
Explanation:
In this scenario, users of a published app report incomplete visualizations, but the data architect is unable to replicate the error. This issue affects only one team, suggesting that the problem is related to how data is being restricted or filtered for that specific team.
* Section Access: This is a security feature in Qlik Sense that controls user access to specific data within an app. If Section Access is misconfigured, it can restrict access to more records than intended, leading to incomplete visualizations for certain users or teams.
* Restricting Too Many Records: If the Section Access is too restrictive, it might limit the data available to the affected users, causing the visualizations to display incomplete information. This could explain why the data architect, who likely has full access, cannot replicate the issue.
NEW QUESTION # 45 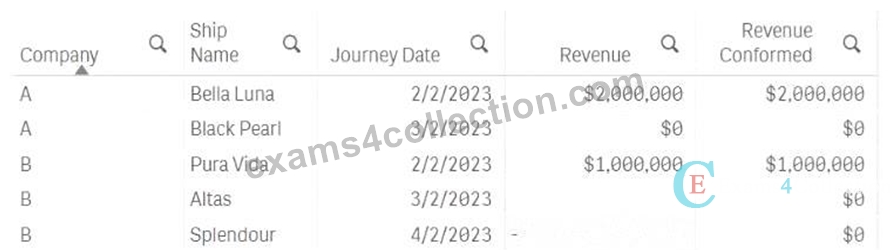
Refer to the exhibit
A large transport company (Company A) acquires a smaller rival (Company B).
Company A has been using Qlik Sense tor 6 years to track revenue per ship journey. Ship journeys with no revenue (such as journeys to shipyards for repair) always show revenue of $0.
Company A wants to combine its data set with the data set of the acquired Company B. Company B's ship journey data shows $0 revenue in one of the following ways:
* A NULL value
* A value with one or more blank spaces (ASCII char code 32)
The data architect wants to conform the Company B data to the Company A standard, specifically regarding the use of an explicit $0 for journeys without revenue. Which script line should the data architect use?
- A.

- B.

- C.

- D.
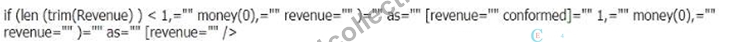
Answer: C
Explanation:
In this scenario, the data architect needs to conform the revenue data from Company B to match the data standard of Company A, where $0 is explicitly used to represent journeys without revenue.
Explanation of the Correct Script:
* Option A:money(replace(Revenue, chr(32), 0)) AS [Revenue Conformed]
* replace(Revenue, chr(32), 0):This part of the expression replaces any spaces (ASCII character code 32) in the Revenue field with 0.
* money(...):This function formats the resulting value as currency. Since Company B may have either null values or spaces where 0 should be, this script ensures that any blanks are replaced with 0 and then formatted as currency.
Why Option A is Correct:
* Handling Spaces:The replace() function is effective in replacing spaces with 0, conforming to Company A's standard of using $0 for non-revenue journeys.
* Handling NULL Values:The money() function is used to ensure the final output is formatted as currency. However, it's important to note that NULL values are not directly handled by the replace() function, which is why it is applied before money() to deal with spaces.
NEW QUESTION # 46
......
Qlik QSDA2024 Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
| Topic 5 |
|
Exam Questions for QSDA2024 Updated Versions With Test Engine: https://easytest.exams4collection.com/QSDA2024-latest-braindumps.html